How We Improved Project Predictability by 102% in 9 Months. You Can Fix Your Company, Too - Pt. 2

They were supposed to share their tools and processes and help us identify what we could improve in ours. In reality, they couldn’t help us. Our predictability was higher than theirs, and they saw no need to improve it any further.
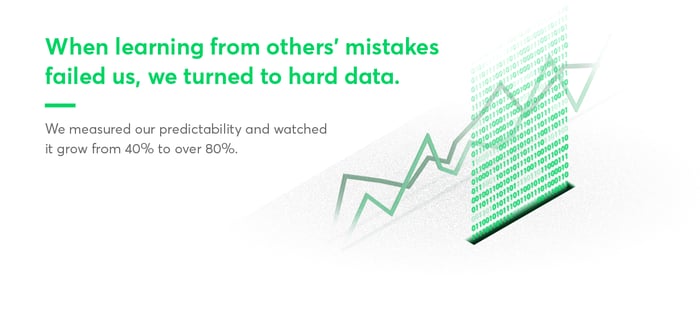
When learning from others’ mistakes failed us, we turned to hard data. In Part 1 of this series, we talked about measuring our predictability at an AAR, after a project. It used to be 40% – we were only able to predict how a project would go with 40-percent accuracy.
That was unacceptable. So we went into change mode and bumped it to about 81%.
This is the second part of our three-article series about improving predictability at software development and consulting companies. Check out Part 1 for background information and advice on introducing a major change to your colleagues. Part 3 offers our step-by-step guide to improving predictability and the next possible steps you might want to take.
1. Estimations - how we used 13th century maths to improve our business
Estimations have a direct impact on how successful sprints are. Until last year, we had used a hybrid model for estimation – a bit of a point-based system and a time-based system. We converted hours (i.e. time) into points, because people can’t correctly estimate hours.
With time, we switched to a points-only system based on the Fibonacci sequence (yes, the 13th century wisdom implemented in modern technology). The basic idea is that you use reference tasks and assign points by comparison to them – not on a scale of 1 to 10, but on one that proceeds from one value to another more rapidly (the modified beginning of the Fibonacci sequence goes as follows: 1, 2, 3, 5, 8, 13…). Points are assigned based on the level of complexity of a task rather than its duration. This approach has its roots in the way our brains work.
2. Cohesive methodology
We have always managed projects the Agile way, but at first, we went with our gut feeling instead of relying on hard facts. Our approach wasn’t systematic enough – we would change our ways depending on particular clients and situations. In the first two quarters of 2017, we decided to consolidate the way we manage projects. It’s not that we’re suddenly super strict, but we now use elements that are set in stone (standups, sprints, retrospectives and demos) around which we base each project’s lifecycle.
We always wanted our methodology to be cohesive. We felt like we had to keep doing things the way we used to (i.e. messily) or commit fully to Scrum. Luckily, we have since accepted that we need to adjust ourselves to the market reality, in the spirit of Agile, and adopt a methodology that fits our needs. Honestly, the rule that you need to be 100% Scrum goes against Agile thinking, and more and more people approach this issue the way we do.

3. Our ecosystem - Jira is the heart of the project, Salesforce is the heart of the business
It’s impossible to start working on predictability without considering the tools you use. The basic structure is as follows: data points + Salesforce + Slack for everyday communication. The most important data goes into Slack, so that we can see what’s happening in real time and in an accessible format.
We also use Jira, which organises our work on every project. It helps us put our thoughts in order and clearly lay out the expectations of the project’s end result. It lets us easily adjust project plans to changing circumstances. To top it all off, Jira has a lot of analytical tools and lets us measure how we’re doing in a given project.
The desired state of affairs was the efficient use of Jira, Salesforce and Slack.

Once we started working with data, we noticed how un-integrated our tools were. We used one tool for scheduling and a different one for client relations. They didn’t merge well, and they couldn’t give us the data we needed to create metrics and make good decisions. So we moved to Salesforce with scheduling and integrated other data points (Jira, Github) with it. Displaying the data in Salesforce in the right context (business and individual project) improved our processes, helped us organise our work, and had a very positive impact on our predictability.
We’re still working on simplifying the ecosystem, though we’ve managed to improve most of what we wanted to improve in 2016. We have two interconnected sources of information. Jira is the heart of the project, and Salesforce is the heart of our business. Jira helps us plan, while Salesforce lets us take a look at each project from the perspective of the whole company. Linking these tools has allowed us to assess project health within Salesforce through KPIs (key performance indicators), without the need for analysing all the elements in Jira.
Some small things still need simplification though. We have too many ‘satellite’ tools, and we’re trying to simplify the tool architecture. We’ll continue to try to improve things forever, most likely. We’re moving towards machine learning now in order to be able to make even faster predictions.
Data is important not only in the context of project management. We try to connect data coming from different departments, and Salesforce helps us do it.
4. Working with data - a single source of truth
We’ve been using Salesforce for the last couple of years. Initially, we treated it as just a standard CRM and took advantage only of the CRM functionalities. With time, we started discovering Salesforce’s full capabilities and used it as our single source of truth (SSOT), especially because it also allows for building multiple versions of the truth (MVOT) (more about these concepts here).
The first step was to move the information about our projects into Salesforce, so that it could become our “Project CRM”. The second big step was to move our scheduling (i.e. the allocation of people to projects) there as well. We looked at the existing professional service automation solutions but, in the end, we decided to create one ourselves. We felt that those other solutions were not yet mature enough to meet our needs. Looking back, we think it was the right decision.
Once we had done that, we decided to aggregate even more data around our projects in Salesforce. We created a tool which calculates a project’s KPIs automatically, using data from JIRA and GitHub (our code repository). It collects data points necessary for calculating KPIs and converts them to project metrics, which allows us to identify potential issues in our projects very early on.
The Key to Predictability: Metrics
Predictability is now just one among the many KPIs we measure. We had to create metrics and learn how to use them, but the effort was worth it. The basic steps were:
- Educating ourselves
- Creating metrics
- Using our new metrics
We began searching for metrics which would help us measure how a given project is doing. We started by having a few meetings with the whole project team. We broke projects into segments and checked whether we could see issues in any of those segments. It wasn’t a simple matter, since we always have quite a few concurrent projects on our hands.
We came up with about 10 KPIs we now measure for each project.
Two are measured based on whole sprints:
- percentage of sprint realisation (how much of the work planned for the sprint was completed before its end);
- tickets added to the sprint after its start and initial planning phase.
The rest we measure weekly, since sprint length is not equal across all our projects:
- points delivered (the point value of tickets);
- average time a ticket waited for a Code Review (in business hours);
- average time a ticket waited for quality analysis (in business hours);
- number of tickets rejected through quality analysis;
- number of reported bugs;
- average number of commits per developer;
- number of commits made by the person (developer) who made the fewest commits.

Using the Metrics
We look at project metrics every week and, based on the data, we judge how healthy our projects are. We measure how much we have achieved in a given sprint in comparison to what was planned for it in the beginning. This translates directly into predictability.
Tracking Process Efficiency
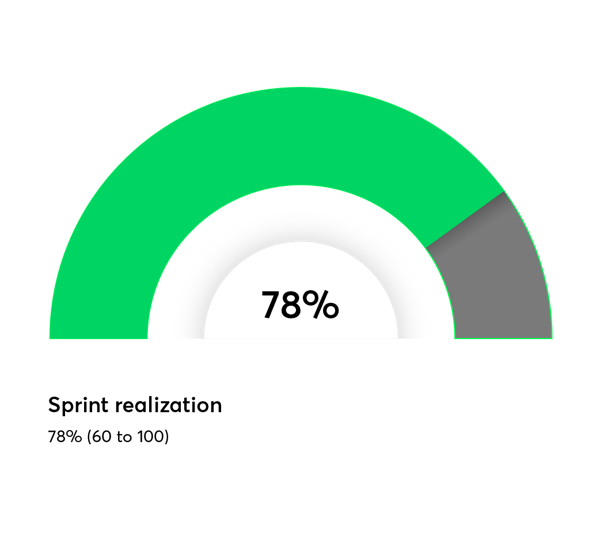
This is the percentage of our completed sprints in September 2017. It’s a fairly motivating result. But it’s not the only factor to take into consideration. We’ve introduced a number of processes that help us gather more exhaustive data and track our results almost in real time.
Project-external PM project review
A regular process in which a PM external to the project looks at how the project is doing, mostly paying attention to data from the tools.
Agile review
Pretty much the same thing, except it’s a deeper look and focuses on methodology. The team has to actively participate.
Project KPIs
They give us a snapshot of the project every week and help us see what challenges the project might face.
Retrospectives
The team analyses the last sprint and makes improvements.
Feedback sessions
We hold feedback sessions for PMs and customer success executives. Ideally, we have the client there as well to learn about their perspective.
When we started with toolset unifications and estimation, we had only a few measures: how long clients stay, why they leave, what feedback they give. That didn’t show us the full picture, so we started searching for hard data. Now, we gather data that helps us measure the effectiveness of our processes on several levels.

Part 2 Conclusions
In this second episode of our three-part article series, we talked about how we took advantage of the data we already gathered, and introduced proper metrics and processes to measure and improve our predictability. Part 1 deals with how important it is to properly predict your business processes and with the difficulties of introducing a major change to your company. Part 3 is our guide for improving predictability in your company.
















.jpg?width=384&height=202&name=Netguru-Biuro-2018-6425%20(1).jpg)













