
Introduction
Machine learning programs build models based on sample data, in order to make predictions or decisions, without being explicitly programmed to do so.
In today’s world, as data has become the lifeblood of successful business, machine learning can be the key to unlocking the value of corporate, customer or commercial data, enhancing data-driven decisions to give businesses a competitive edge.
While machine learning might be primarily seen as a ‘tech’ pursuit, it can be applied to almost any business industry, such as retail, healthcare or fintech. Any industry that generates data on its customers and activities can use machine learning to process and analyse that data to inform their strategic objectives and business decisions.
In this guide, we’ll be covering everything you need to know about machine learning, from its history to its modern approaches, how it differs from artificial intelligence, potential applications and real life use cases to demonstrate them.
We’ll also run through some of the jargon related to machine learning and, importantly, explain the opportunities and challenges open to businesses looking to use it.
Machine learning definition
The MIT Technology Review definition of machine learning is this:
Machine-learning algorithms use statistics to find patterns in massive* amounts of data. And data, here, encompasses a lot of things—numbers, words, images, clicks, what have you. If it can be digitally stored, it can be fed into a machine-learning algorithm.
That’s a concise way to describe it, but there are, of course, different stages to the process of developing machine learning systems.
As mentioned briefly above, machine learning systems build models to process and analyse data, make predictions and improve through experience. To put it more simply another way, they use statistics to find patterns in vast amounts of data.
As such, they are vitally important to modern enterprise, but before we go into why, let’s take a closer look at how machine learning works.
Machine learning systems are built on three major parts, which are:
- Model is the system that makes all the predictions and identifications.
- Parameters are the factors used by the model to form its decisions.
- Learner is the system that adjusts the parameters and revamps the model by looking at differences in predictions versus actual outcome.
Model
First of all, the model that makes all the predictions needs to be applied to a computer (by a living breathing person), and then, this model needs to be programmed accordingly in order to study the particular activity that’s integrated into the system, such as the time for task completion from the example above.
Parameters
Such a model relies on parameters to evaluate what the optimal time for the completion of a task is.
Learner
This data applied to the machine learning system is usually called the ‘training set’ or ‘training data’, and it’s used by the learner to align the model and continually improve it. Also, the learner can rework predictions depending on the different results it records over time. It makes very small adjustments to the parameters to refine the model.
Machine learning uses a mathematical equation to define all of the points above. So this is how the trend is formed – the computer can make accurate predictions over time and interpret real-life information.
Once the machine learning system is built, there are three primary categories of use:
- Supervised learning - in which the ML system is trained on the basis of data samples with previously known results for each sample
- Unsupervised learning - in which the ML system finds internal relationships and patterns in the data, with results for each example unknown
- Reinforcement learning - in which the system is ‘rewarded’ for correct actions (and penalised for incorrect ones). As a result, the system learns to develop algorithms in which it receives the highest reward and the lowest penalty
Why is machine learning important?
Machine learning isn’t a new concept, but it’s popularity has exploded in recent years because it can help address one of the key issues businesses face in the contemporary commercial landscape. Namely, incorporating analytical insights into products and real-time services to make customer targeting much more accurate.

Computing advances have enabled the mass collection of the raw data required to do this, but machine learning makes it possible to effectively analyse that data to make better, more informed business decisions.
Working with ML-based systems can be a game-changer, helping organisations make the most of their upsell and cross-sell campaigns. Simultaneously, ML-powered sales campaigns can help you simultaneously increase customer satisfaction and brand loyalty, affecting your revenue remarkably. This is an investment that every company will have to make, sooner or later, in order to maintain their competitive edge.
Let’s use the retail industry as a brief example, before we go into more detailed uses for machine learning further down this page. For retailers, machine learning can be used in a number of beneficial ways, from stock monitoring to logistics management, all of which can increase supply chain efficiency and reduce costs.

Simply put, machine learning is vital to business because it enables organizations to better understand and cater to their target market - boosting productivity and reducing the time human employees need to spend analysing data.
Machine Learning vs. Artificial Intelligence
Machine Learning and Artificial Intelligence (AI) are concepts that are often confused for each other. While they are definitely intertwined, they remain distinct concepts with key differences.
Before we go through those Machine Learning vs Artificial Intelligence, let’s define AI.
In Francois Chollet’s book Deep Learning with Python, AI is defined as:
the effort to automate intellectual tasks normally performed by humans. As such, AI is a general field that encompasses machine learning and deep learning, but also includes many more approaches that don’t involve any learning.
So, what is the difference between AI and machine learning?
As you can see from the above representation, AI represents the broad field within which Machine Learning sits.
To put this relationship into words:
AI is the broader concept of machines carrying out tasks we consider to be ‘smart’, while...
Machine Learning is a current application of AI, based on the idea that machines should be given access to data and able to learn for themselves.
One of the key aspects of intelligence is the ability to learn and improve. For AI, machine learning models enable this ability. They are unlike classic algorithms, which use clear instructions to convert incoming data into a predefined result. Instead, they use examples of data and corresponding results to find patterns, producing an algorithm that converts arbitrary data to a desired result.

Within machine learning are neural networks and deep learning.
A neural network is a series of algorithms that attempt to recognize underlying relationships in datasets via a process that mimics the way the human brain operates. These neural networks are made up of multiple ‘neurons’, and the connections between them. Each neuron has input parameters on which it performs a function to deliver an output.
Deep learning, meanwhile, deals with deep neural networks. Deep learning is part of a broader family of machine learning methods based on neural networks with representation learning. Learning can be supervised, semi-supervised or unsupervised.
To zoom back out and summarise this information, machine learning is a subset of AI methods, and AI is the general concept of automating intelligent tasks.
Machine learning approaches

The process of building machine learning models can be broken down into a number of incremental stages, designed to ensure it works for your specific business model.
At Netguru, we have a broad, 4-step process, incorporating: Discover, Design, Prototype and Improve.
Discover
In the discovery phase, we conduct Discovery Workshops to identify opportunities with high business value and high feasibility, set goals and a roadmap with the leadership team.
We define the right use cases by Storyboarding to map current processes and find AI benefits for each process. Next, we assess available data against the 5VS industry standard for detecting Big Data problems and assessing the value of available data.
As the discovery phase progresses, we can begin to define the feasibility and business impact of the machine learning project. Mapping impact vs feasibility visualizes the trade-offs between the benefits and costs of an AI solution.
Once all of these assessments are carried out, you will have a bigger picture of the range of ML options available to your business, and be able to prioritize use cases and workflow set a clear roadmap of AI adoption for maximizing your return on investment.
This process takes 1-2 days, on average.
Design
Next, conducting design sprint workshops will enable you to design a solution for the selected business goal and understand how it should be integrated into existing processes.
Together, we’ll help you design a complete solution based on data and machine learning usage and define how it should be integrated with your existing processes and products.
By first defining a business problem and the solution to it, you can then conceptualize a data science solution, before using Data and Model Flow Diagrams to build flows of how the ML will interact with live data and learn, putting the tech behind the idea.
On average, this stage of the process takes about 2-3 days.
Prototype
After design, we move on to the prototype stage, in which we develop a proof of concept, before implementing it for a selected business goal.
This stage begins with data preparation, in which we define and create the golden record of the data to be used in the ML model. It’s also important to conduct exploratory data analysis to identify sources of variability and imbalance.
Once this is done, modeling can begin, by expressing the chosen solution in terms of equations specific to an ML method.
Then the prototyping begins. This involves training and evaluating a prototype ML model to confirm its business value, before encapsulating the model in an easily-integrable API (Application Programme Interface), so it can be deployed.
On average, this stage takes around 4-6 weeks.
Improve
Once your prototype is deployed, it’s important to conduct regular model improvement sprints to maintain or enhance the confidence and quality of your ML model for AI problems that require the highest possible fidelity.
This is an iterative process, and includes feature engineering, model architecture design and learning algorithm design.
We run multiple training experiments, hyperparameter optimization and evaluate model performance, before packaging the model for final full deployment, to ensure you can hit the ground running with the benefits of your new ML model.
On average, each ‘model improvement sprint’ takes about two weeks.
How can it be used?
Of course, the most important thing about machine learning is its potential business applications. We’ve covered a couple of general use cases above, but for more specific examples, let’s take a look at some case studies.
Fraud detection
Alert about suspicious transactions - fraud detection is important not only in the case of stolen credit cards, but also in the case of delayed payments or insurance. Machine learning algorithms can be used to analyse data to detect fraudulent activities - crucial in banking, insurance, retail and a number of other industries.
In one case, we developed a plug-and-play baseline that is supposed to work out-of-the-box with tabular data and benchmarked it against solutions available in the web.
Speech-to-Text transcription
Machine learning is the system that underpins speech recognition software, using natural language processing and other AI-based concepts to render speech into text, accurately, whether that’s for video subtitles, taking notes or even ordering items online, through voice activities digital assistants like Amazon’s Alexa or Google Home.
We used an ML model to help us build CocoonWeaver, a speech-to-text transcription app. We have designed an intuitive UX and developed a neural network that, together with Siri, enables the app to perform speech-to-text transcription and produce notes with correct grammar and punctuation.
Personalized shopping
E-commerce and mobile commerce are industries driven by machine learning. Ml models enable retailers to offer accurate product recommendationsto customers and facilitate new concepts like social shopping and augmented reality experiences.
We put this in practice when developing an app for Countr. Countr is a personalized shopping app that enables its users to shop with their friends, receive trusted recommendations, showcase their style, and earn money for their taste – all in one place. When it comes to ML, we delivered the recommendation and feed-generation functionalities and improved the user search experience.
Insurance and finance use cases
While most of the above examples are applicable to retail scenarios, machine learning can also be applied to extensive benefit in the insurance and finance industries.
These are industries that are heavily regulated, with strict processes that handle massive amounts of requests, transactions and claims every day. As such, machine learning models can build intelligent automation solutions to make these processes quicker, more accurate and 100% compliant.
In addition, machine learning can be used to help evaluate risks to find the best price matches for insurance and finance providers.
Many insurers still rely on traditional methods when evaluating risk. For example, when calculating property risks, they may use historical data for a specific zip code. Individual customers are often assessed using outdated indicators, such as credit score and loss history.
In this context, machine learning can offer agents new tools and methods supporting them in classifying risks and calculating more accurate predictive pricing models that eventually reduce loss ratios.
Other use cases include improving the underwriting process, better customer lifetime value (CLV) prediction, and more appropriate personalization in marketing materials.
These are some broad-brush examples of the uses for machine learning across different industries.
There are too many potential applications of machine learning to put down an exhaustive list, but the key takeaway is that whatever the nature of your business, machine learning has the potential to help enhance performance and customer experience alike.
What does machine learning change?

In today’s connected business landscape, with countless online interactions and transactions conducted every day, businesses collect massive amounts of raw data on supply chain operations and customer behavior.
That data can be incredibly useful, but without a way to parse it, analyze and understand it, it can be burdensome instead. Machine learning enables the systems that make that analysis easier and more accurate, which is why it’s so important in the modern business landscape.
One of the biggest challenges for businesses nowadays is incorporating analytical insights into products and real-time services to make customer targeting much more accurate.
Working with ML-based systems can help organizations make the most of your upsell and cross-sell campaigns. ML-powered sales campaigns can help you simultaneously increase customer satisfaction and brand loyalty, affecting your revenue remarkably.
Meanwhile, marketing informed by the analytics of machine learning can drive customer acquisition and establish brand awareness and reputation with the target markets that really matter to you.
As more industries and individual businesses begin to integrate machine learning to these ends, it will become ever more imperative for others to do the same, or risk falling behind with less efficient legacy systems.
History and relationships to other fields
The term machine learning was coined in 1959 by Arthur Samuel, an American pioneer in the field of computer gaming and artificial intelligence.
A representative book of the machine learning research during the 1960s was the Nilsson's book on Learning Machines, dealing mostly with machine learning for pattern classification.
Interest related to pattern recognition continued into the 1970s, as described by Duda and Hart in 1973.
In 1981 a report was given on using teaching strategies so that a neural network learns to recognize 40 characters (26 letters, 10 digits, and 4 special symbols) from a computer terminal
Tom M. Mitchell provided a more formal definition of the algorithms studied in the machine learning field:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.
This definition of the tasks in which machine learning is concerned offers an operational definition rather than defining the field in cognitive terms.
Modern day machine learning has two objectives, one is to classify data based on models which have been developed, the other purpose is to make predictions for future outcomes based on these models. A hypothetical algorithm specific to classifying data may use computer vision of moles coupled with supervised learning in order to train it to classify the cancerous moles.
Whereas, a machine learning algorithm for stock trading may inform the trader of future potential predictions.
After this brief history of machine learning, let’s take a look at its relationship to other tech fields.
Ruby on Rails in Machine Learning
Ruby on Rails is a programming language which is commonly used in web development and software scripts.
With the Ruby on Rails framework, software developers can build minimum viable products (MVPs) in a way which is both fast and stable. This is thanks to the availability of various packages called gems, which help solve diverse problems quickly.
When looking at Machine Learning gems, the choice is not that rich. Often, the problem is that the described solutions are not documented enough, so the large datasets required to train machine learning models are not available.
They also do not provide efficient computation speed and only have a small community of developers. These factors show that there are more risks than advantages when using Ruby gems as Machine Learning solutions. For business requiring high computation speeds and mass data processing, this is not ideal.
Moreover, tools and packages are as useful as the language of development. Ruby is definitely one of the most interesting programming languages. It has many proven purposes, but fast computing is not one of them. As such, Ruby on Rails does not facilitate successful machine learning development.
Python in Machine Learning
Python is a much better option for machine learning systems.
Python is one of the most popular programming languages in the world. Favoured for applications ranging from web development to scripting and process automation, Python is quickly becoming the top choice among developers for artificial intelligence (AI), machine learning, and deep learning projects.
One of the aspects that makes Python such a popular choice in general, is its abundance of libraries and frameworks that facilitate coding and save development time, which is especially useful for machine learning and deep learning.
Python is renowned for its concise, readable code, and is almost unrivaled when it comes to ease of use and simplicity, particularly for new developers. This has several advantages for machine learning and deep learning.
Python’s simple syntax means that it is also faster application in development than many programming languages, and allows the developer to quickly test algorithms without having to implement them.
In addition, easily readable code is invaluable for collaborative coding, or when machine learning or deep learning projects change hands between development teams. This is particularly true if a project contains a great deal of custom business logic or third party components.
Python is an open-source programming language and is supported by a lot of resources and high-quality documentation. It also boasts a large and active community of developers willing to provide advice and assistance through all stages of the development process.
While other programming languages can also be used in AI projects, there is no getting away from the fact that Python is at the cutting edge, and should be given significant consideration when embarking on any machine learning project.
Google Cloud and Machine Learning
The cloud platform by Google is a set of tools dedicated for various actions, including machine learning, big data, cloud data storage and Internet of Things modules, among other things.
Google Cloud offers various Machine Learning tools which can extend your project with AI components easily. It can be integrated into your existing projects without having to maintain and set up additional infrastructure.
First of all, the most general one is called Machine Learning Cloud. You can build, store, and perform your own Machine Learning structures, like Neural Networks, Decision Trees, and Clustering Algorithms on it. The biggest advantage of using this technology is the ability to run complex calculations on strong CPUs and GPUs. This way, you don’t have to buy and maintain your own powerful servers.
Another advantage is payments. Building your own infrastructure requires bigger initial costs and continuous maintenance. With Google Cloud you just pay per usage, for example 1 hour of running complex calculations.
The next option would be a more specific solution, called Natural Language Processing Cloud. The service is dedicated to processing blocks of text and fetching information based on that. The biggest advantage of using NLP Cloud is that you don't have to define your own processing algorithms.
The service brings its own huge database of already learnt words, which allows you to use the service immediately, without preparing any databases. This way you can discover various information about text blocks by simply calling an NLP cloud service.
Alternatively, the Computer Vision Cloud enables the semantic recognition of images. Google comes with a trained model dedicated to recognizing objects in image files. Just call the Computer Vision Cloud service with an image attachment and collect information about the content inside.
All of this makes Google Cloud an excellent, versatile option for building and training your machine learning model, especially if you don’t have the resources to build these capabilities from scratch internally.
Types of machine learning algorithms
There are a number of different frameworks available for use in machine learning algorithms.
It’s crucial to remember that the technology you work with must be paired with an adequate deep learning framework, especially because each framework serves a different purpose. Finding that perfect fit is essential in terms of smooth and fast business development, as well as successful deployment.
The following list of deep learning frameworks might come in handy during the process of selecting the right one for the particular challenges that you’re facing. Compare the pros and cons of different solutions, check their limitations, and learn about best use cases for each solution.
TensorFlow
Created by Google and written in C++ and Python, TensorFlow is perceived to be one of the best open source libraries for numerical computation. Tech giants like DeepMind, Uber, AirBnB, and Dropbox have all decided to leverage this framework.
TensorFlow is good for advanced projects, such as creating multilayer neural networks. It’s used in voice/image recognition and text-based apps (like Google Translate).
Here are some of the more technical pros and cons for Tensorflow:
Pros:
- It has a lot of documentation and guidelines;
- It offers monitoring for training processes of the models and visualization (Tensorboard);
- It’s backed by a large community of devs and tech companies;
- It supports distributed training;
- Tensorflow Lite enables on-device inference with low latency for mobile devices;
- Tensorflow JS enables deploying models in JavaScript environments, both frontend and Node.js backend. TensorFlow.js also supports defining models in JavaScript and training them directly in the browser using a Keras-like API.
Cons:
- It struggles with poor results for speed in benchmark tests compared with, for example, CNTK and MXNet,
- It has a higher entry threshold for beginners than PyTorch or Keras. Plain Tensorflow is pretty low-level and requires a lot of boilerplate coding,
- And the default Tensorflow “define and run” mode makes debugging very difficult.
PyTorch
PyTorch is the Python successor of Torch library written in Lua and a big competitor for TensorFlow. It was developed by Facebook and is used by Twitter, Salesforce, the University of Oxford, and many others.
PyTorch is mainly used to train deep learning models quickly and effectively, so it’s the framework of choice for a large number of researchers.
Pros:
- The modeling process is simple and transparent thanks to the framework’s architectural style;
- The default define-by-run mode is more like traditional programming, and you can use common debugging tools as pdb, ipdb or PyCharm debugger;
- It has declarative data parallelism;
- It features a lot of pretrained models and modular parts that are ready and easy to combine;
- It supports distributed training.
- It is production-ready since version 1.0.
Cons:
- Third-party needed for visualization.
- API server needed for production.
Keras
This is a minimalistic Python-based library that can be run on top of TensorFlow, Theano, or CNTK. It was developed by a Google engineer, Francois Chollet, in order to facilitate rapid experimentation. It supports a wide range of neural network layers such as convolutional layers, recurrent layers, or dense layers.
One can make good use of it in areas of translation, image recognition, speech recognition, and so on.
Pros:
- Prototyping is really fast and easy;
- It’s lightweight in terms of building DL models with a lot of layers;
- It features fully-configurable modules;
- It has a simplistic and intuitive interface – fantastic for newbies;
- It has built-in support for training on multiple GPUs;
- It can be turned into Tensorflow estimators and trained on clusters of GPUs on Google Cloud;
- It can be run on Spark;
- It supports NVIDIA GPUs, Google TPUs, and Open-CL-enabled GPUs such as AMD.
Cons:
- It might be too high-level and not always easy to customize;
- It is constrained to Tensorflow, CNTK, and Theano backends.
Keras also doesn’t provide as many functionalities as TensorFlow, and ensures less control over the network, so these could be serious limitations if you plan to build a special type of DL model.
The Keras interface format has become a standard in the deep learning development world. That is why, as mentioned before, it is possible to use Keras as a module of Tensorflow. It makes development easier and reduces differences between these two frameworks. It also combines the advantages of using each of them.
MXNet
This is a DL framework created by Apache, which supports a plethora of languages, like Python, Julia, C++, R, or JavaScript. It’s been adopted by Microsoft, Intel, and Amazon Web Services.
The MXNet framework is known for its great scalability, so it’s used by large companies mainly for speech and handwriting recognition, NLP, and forecasting.
Pros:
- It’s quite fast, flexible, and efficient in terms of running DL algorithms;,
- It features advanced GPU support, including multiple GPU mode;
- It can be run on any device;
- It has a high-performance imperative API;
- It offers easy model serving;
- It’s highly scalable;
- It provides rich support for many programming languages, such as Python, R, Scala, Javascript, and C++, among others;
Cons:
- It has a much smaller community behind it compared with Tensorflow;
- It’s not so popular among the research community.
So, MXNet is a good framework for big industrial projects, but since it is still pretty new, there’s a chance that you won’t receive support exactly when you need it – keep that in mind.
CNTK
This is now called The Microsoft Cognitive Toolkit – an open-source DL framework created to deal with big datasets and to support Python, C++, C#, and Java.
CNTK facilitates really efficient training for voice, handwriting, and image recognition, and supports both CNNs and RNNs. It is used in Skype, Xbox and Cortana.
Pros:
- It delivers good performance and scalability;
- It features a lot of highly optimized components;
- It offers support for Apache Spark;
- It’s very efficient in terms of resource usage;
- It supports simple integration with Azure Cloud;
Cons:
- Limited community support
Caffe and Caffe2
Caffe is a framework implemented in C++ that has a useful Python interface and is good for training models (without writing any additional lines of code), image processing, and for perfecting existing networks.
However, it’s sometimes poorly documented, and difficult to compile.
Caffe2 was introduced by Facebook in 2017, a natural successor to the old Caffe, built for mobile and large-scale deployments in production environments.
At Facebook, it’s known as:
the production-ready platform, (...) shipping to more than 1 billion phones spanning eight generations of iPhones and six generations of Android CPU architectures.
In May 2018 Caffe2 was merged into the PyTorch 1.0 stable version. Now we can consider the pros below as a part of PyTorch.
The framework is praised for several reasons:
- It offers pre-trained models for building demo apps;
- It’s fast, scalable, and lightweight;
- It works well with other frameworks, like PyTorch, and it’s going to be merged into PyTorch 1.0;
- It has server optimized inference.
Opportunities and challenges for machine learning in business
As we’ve already explored, there is a huge potential for machine learning to optimize data-driven decision-making in a number of business domains. However, being data-driven also means overcoming the challenge of ensuring data availability and accuracy. If the data you use to inform and drive business decisions isn’t reliable, it could be costly.
In order to help you navigate these pitfalls, and give you an idea of where machine learning could be applied within your business, let’s run through a few examples. These examples can apply to almost all industry sectors, from retail to fintech.
Pricing Optimization
Dynamic price optimization is becoming increasingly popular among retailers. Machine learning has exponentially increased their ability to process data and apply this knowledge to real-time price adjustments.
Intelligent price optimization is possible thanks to the powerful data processing capabilities that machine learning possesses. It gives retailers an opportunity to regularly adjust prices, taking into consideration market needs, customers’ expectations, and many other factors that the algorithm is being “fed”.
Traditionally, price optimization had to be done by humans and as such was prone to errors. Having a system process all the data and set the prices instead obviously saves a lot of time and manpower and makes the whole process more seamless. Employees can thus use their valuable time dealing with other, more creative tasks.
The other benefit: you can follow the market and set prices in a more flexible way. Thanks to machine learning, pricing is adjusted in a data-driven, complex way, not just using fragmented data and uncertain projections, as is the case with more traditional methods.
One challenge associated with intelligent pricing optimization is whether customers will accept price fluctuations. This has to be assessed on a case-by-case basis, but the good news is that algorithms can help businesses in this process.
Keep in mind that you will need a lot of data for the algorithm to function correctly. But you will only have to gather it once, and then simply update it with the most current information. If done properly, you won’t lose customers because of the fluctuating prices, but maximizing potential profit margins.
Headline & Image Personalization
In the uber-competitive content marketing landscape, personalization plays an ever greater role. Nobody can write for everybody. The more you know about your target audience and the better you’re able to use this set of data, the more chances you have to retain their attention.
Marketing campaigns targeting specific customer groups can result in up to 200% more conversions versus campaigns aimed at general audiences. According to braze.com, 53% of marketers claim a 10% increase in business after they customized their campaigns.
On the other hand, 83% of marketing creatives see content personalization as their top challenge and 60% of businesses struggle to produce content consistently, while 65% find it challenging to produce engaging content.
To try to overcome these challenges, Adobe is using AI and machine learning. They developed a tool that automatically personalizes blog content for each visitor. Using Adobe Sensei, their AI technology, the tool can suggest different headlines, blurbs, and images that presumably address the needs and interests of the particular reader.
Individualization works best when the targeting of a specific group happens in a genuine, human way; when there’s empathy behind the process that allows for the hard-to-achieve connection. We want to read content from authors who “speak our language”.
If the headline is not relevant to the content, it might seem like clickbait and push readers away instead of attracting them to engage with the whole text. And this, whether written by AI or a human, won’t work in the long term.
The fight for attention that we are currently experiencing will only keep intensifying, as will the search for tools that could help one win. The ones that are taking on personalization but are not trying to change too much are best positioned to succeed.
Product Recommendation
A product recommendation system is a software tool designed to generate and provide suggestions for items or content a specific user would like to purchase or engage with. Utilizing machine learning techniques, the system creates an advanced net of complex connections between products and people.
We interact with product recommendation systems nearly every day – during Google searches, using movie or music streaming services, browsing social media or using online banking/eCommerce sites.
As such, product recommendation systems are one of the most successful and widespread applications of machine learning in business.
When configured correctly, they can significantly boost sales, revenues, click-through-rates, conversions, and other important metrics, because personalizing product or content recommendations to a particular user’s preferences improves user experience.
Product recommendation systems face certain challenges in their deployment in order to be effective. One of them is the ‘cold start’ problem, of which there are two kinds: user cold start and product cold start.
The user cold start problem pertains to the lack of information a system has about users that click onto websites for the first time. Similarly, new products have no reviews, likes, clicks, or other successes among users, so no recommendations can be made.
One solution to the user cold start problem is to apply a popularity-based strategy. Trending products can be recommended to the new user in the early stages, and the selection can be narrowed down based on contextual information – their location, which site the visitor came from, device used, etc. Behavioral information will then “kick in” after a few clicks, and start to build up from there.
When it comes to the product cold start problem the product recommendation system can use metadata about the new product when creating recommendations.
Data sparsity and data accuracy are some other challenges with product recommendation. These problems can be solved by combining collaborative filtering with Naïve Bayes or by making recommendations based on both the habits of similar users as well as offering products that share characteristics with other products the user has rated highly.
Trading & money management

To give you an idea of the importance of deep learning and machine learning in the finance sector, take this quote from Aldous Birchall, Head of Financial Services AI at PwC:
I would go so far as to say that any asset manager or bank that engages in strategic trading will be seriously competitively compromised within the next five years if they do not learn how to use this technology.
For many years it seemed that machine-led deep market analysis and prediction was so near and yet so far. Today, as business writer Bryan Borzykowski suggests, technology has caught up and we have both the computational power and the right applications for computers to beat human predictions.
One of the hottest trends in AI research is Generative Adversarial Networks (GANs). GANs are perceived as a big future technology in trading, as well as having uses in asset and derivative pricing or risk factor modelling. Using new models to make rapid advances in the way AI deals with unstructured data, GANs are able to solve a lot of the problems that AI has so far struggled to deal with using the limited and noisy data created in the banking industry.
A specific example of machine learning in banking is CitiBank. Citi Private Bank has been using machine learning to share - anonymously - portfolios of other investors to help its users determine the best investing strategies.
While this is not an exhaustive list of machine learning opportunities and challenges in business, it should nonetheless give you an idea of the potential scope of machine learning - whatever industry you’re in, it can certainly be used somehow.
Advantages and disadvantages of Machine Learning
Machine Learning has many potential upsides, but it’s not always the right choice. Let’s run through some of the advantages and disadvantages it can bring.
Potential advantages of machine learning
- Identification of trends and patterns - This is perhaps the most obvious advantage. Machine learning can easily process, manage and identify patterns in data that would not be apparent to humans. For Amazon, for example, it can understand the browsing and purchase behavior of its users to reveal relevant products, offers & adverts to them.
- Removes the need for human intervention - Because machine learning models can operate independently, making predictions and improving the algorithm on their own, they don’t need human oversight. This can free up resources to be best used elsewhere.
- Continuous Improvement - By definition, machine learning algorithms are always learning and improving, which enables them to make better decisions over time. As the amount of data you collect grows, so too does the accuracy of analysis, because the ML model has a wider pool of information to learn from.
- Handling multi-dimensional, multi-variety data - ML algorithms are adept at managing multi-dimensional data, where data files contain one or more variables, and can operate just as efficiently in dynamic or uncertain environments.
- Broad potential applications - As we’ve covered already, there are almost countless ways machine learning can be used in business. Whether you are an eCommerce provider or a healthcare organization, machine learning can help you refine and optimize individual customer targeting.
Potential disadvantages of machine learning
- Data Acquisition - For ML models to get started and be successful, they need massive data sets to train on. Furthermore, the data needs to be inclusive, unbiased and of good quality. This data can be tricky for some organizations to collect.
- Time and Resources - although machine learning systems can save time and free up human resources once they’re up and running, it takes time for algorithms to get up to speed as they learn and develop. This can require additional computing power, and obviously time taken by humans to feed that data in the first place.
- Interpretation of results - It can sometimes be a challenge to choose the right algorithm to suit your business objective and to correctly interpret the results that algorithm delivers. Sometimes, outputs might contain errors, which have to be checked and corrected.
- High-error susceptibility - Machine learning models act autonomously and react to different data in different ways, and as such are prone to errors. For example, if you train your Ml model with a data set that is not fully-inclusive (ie a biased training set), you could end up with biased predictions that don’t reflect the reality of the scenario. This could set off a chain of errors that can go undetected for long periods of time, and take even longer to correct.
Applying machine learning to IoT
One area this guide hasn’t yet covered in detail is Internet of Things (IoT).
The Internet of things describes the network of physical objects—“things”—that are embedded with sensors, software, and other technologies for the purpose of connecting and exchanging data with other devices and systems over the Internet.

These devices - such as smart TVs, wearables, and voice-activated assistants - generate huge amounts of data. As machine learning is powered by and learns from data, there is an obvious intersection between these two concepts.
Machine learning can be used to identify the patterns hidden within the reams of data collected by IoT devices, thereby enabling these devices to automate data-driven actions and critical processes.
With machine learning for IoT, you can ingest and transform data into consistent formats, and deploy an ML model to cloud, edge and devices platforms.
IoT machine learning can simplify machine learning model training by removing the challenge of data acquisition and sparsity. It can also enable rapid model deployment to operationalize machine learning quickly.
This report by Science Direct identifies three key trends and facts regarding machine learning for IoT:
“The first is that different applications in IoT… have their own characteristics, such as the number of devices and types of the data that they generate. The second is that the generated data will have specific features that should be considered. The third is that the taxonomy of algorithms is another important aspect in applying data analysis to smart data.”
The key takeaway from the report, and from the general IoT trend, is that machine learning is needed to underpin the success of any IoT device, whether that’s a single smart watch or a much bigger network of devices making up a smart city. The ability to ingest, process, analyze and react to massive amounts of data is what makes IoT devices tick, and its machine learning models that handles those processes.
Use of machine learning in various industries

Fintech and banking
Fintech refers to the integration of technology into offerings by financial services companies in order to improve their use and delivery to the consumer. It is a growing and global market, estimated to reach a massive $305 billion by 2025, growing at a compound annual rate of around 22.17% between 2020-25.
Naturally, where the integration of technology is key, there are a number of potential applications for machine learning in fintech and banking.
Customer service
Chatbots and AI interfaces like Cleo, Eno, and the Wells Fargo Bot interact with customers and answer queries, offering massive potential to cut front office and helpline staffing costs. The London-based financial-sector research firm Autonomous produced a reportwhich predicts that the finance sector can leverage AI technology to cut 22% of operating costs - totaling a staggering $1 trillion.
In the back and middle office, AI can be applied in areas such as underwriting, data processing or anti-money laundering.
Natural Language Processing (NLP) is really the key here - utilizing deep learning algorithms to understand language and generate responses in a more natural way. Swedbank, which has over a half of its customers already using digital banking, is using the Nina chatbot with NLP to try and fully resolve 2 million transactional calls to its contact center each year.
Risk Management
Applications like Lenddo are bridging the gap for those who want to apply for a loan in the developing world, but have no credit history for the bank to review. Potential borrowers sign up and allow the app to mine their data from social media, web browser history, geo-locations, and other information, to build a picture that allows banks to assess if they are creditworthy or not--without any of the traditional metrics that make up the credit rating.
And there is clearly appetite among the estimated 600 million potential lenders in developing countries who banks will not consider, as the startup managed to attract 350,000 users in just 2 years from launch.
In the developed world, social media (SoMe) data is used by microloan companies like Affirm in what they term a ‘soft’ credit score. They don’t need to compile a full credit history to lend small amounts for online purchasing, but SoMe data can be used to verify the borrower and do some basic background research.
This is similar to some car loan companies, like Neo, which use LinkedIn profiles to verify that a person’s stated work history is genuine, cross-checking listed jobs against a user’s contacts on the site.
Regulatory compliance
The advancement of AI and ML technology in the financial branch means that investment firms are turning on machines and turning off human analysts. Research firm Optimas estimates that by 2025, AI use will cause a 10 per cent reduction in the financial services workforce, with 40% of those layoffs in money management operation.
But there are increasing calls to enhance accountability in areas such as investment and credit scoring. Artificial Intelligence can be used to calculate and analyse cash flows and predict future scenarios, for example, but it does not explain the logic or processes it used to reach a conclusion.
Explainable AI is a response to this specific problem: calling for machines to explain their reasoning, particularly in areas like loan refusals, where their decisions directly affect humans. And in the GDPR-era this is a major issue. Banks want to leverage the technology, but they need to do so in an accountable way.
Retail
As covered above, machine learning can be used for various functions across the retail supply chain, from stock and logistics management to pricing optimization and product recommendation.
Intelligent price optimization gives retailers an opportunity to regularly adjust prices, taking into consideration market needs, customers’ expectations, and other factors.
When configured correctly, product recommendation systems can significantly boost sales, revenues, click-through-rates, conversions, and other important metrics, because personalizing product or content recommendations to a particular user’s preferences improves user experience.
This ties in to the broader use of machine learning for marketing purposes. Personalization and targeted messaging, driven by data-based ML analytics, can ensure more effective use of marketing resources and a higher chance of establishing brand awareness within appropriate target markets.
With regards to stock optimization and logistics management, machine learning models can be used to deliver predictive analytics to ensure optimal stock levels at all times, reducing inventory loss or wastage.
Healthcare
In healthcare, getting the diagnosis right – and getting it in time – is key to any successful treatment. It’s a matter of utmost importance, as revealed in the research on postmortem examinations: diagnostic errors are responsible for about 10% of patient deaths in total. The study also suggests that these errors contribute to 6-17% of all adverse events in hospitals.
As artificial neural networks excel in mapping patterns from data to specific outcome, they’ve also turned out to be extremely useful and accurate in medical diagnosis, which in most situations is dependent on a complex interaction of many clinical, biological and pathological variables.
Machine learning techniques are also leveraged to analyze and interpret large proteomics datasets. Researchers make use of these advanced methods to identify biomarkers of disease and to classify samples into disease or treatment groups, which may be crucial in the diagnostic process – especially in oncology.
Also, chatbots have the potential to significantly ease the burden on healthcare providers (HCPs), reduce costs, and provide personalized health and therapy information to patients, providing quicker access to care, automating administrative tasks and making care proactive.
Examples of machine learning implementation
Here are a few case studies of machine learning implementation, which we’ve worked on here at Netguru:
Countr
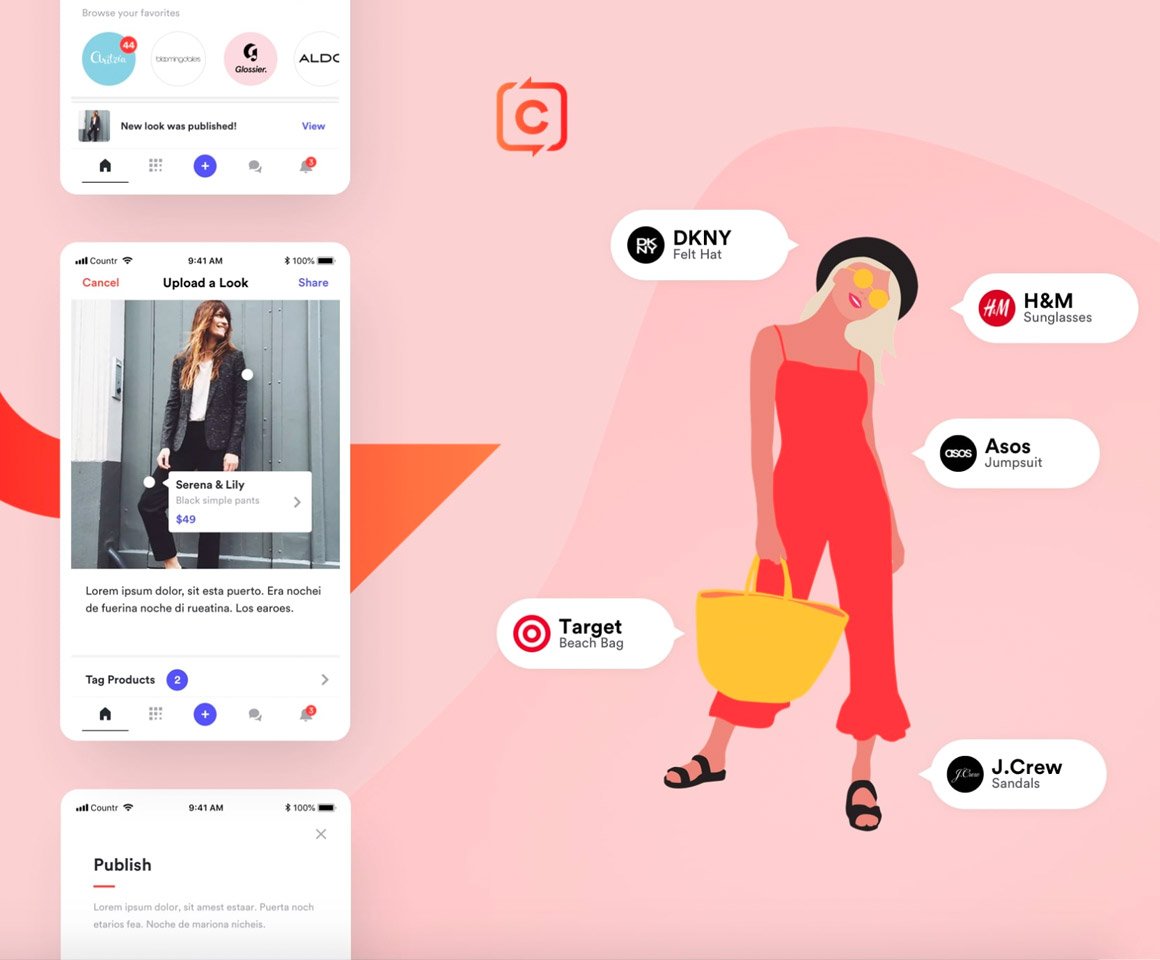
Countr is a personalized shopping app that enables its users to shop with their friends, receive trusted recommendations, showcase their style, and earn money for their taste – all in one place.
Using machine learning models, we delivered recommendation and feed-generation functionalities and improved the user search experience.
Read the full case study here.
CocoonWeaver
We designed an intuitive UX and developed a neural network that, together with Siri, enables the app to perform speech-to-text transcription and accurately produce notes with correct grammar and punctuation.
Read the full case study here.
Kunster
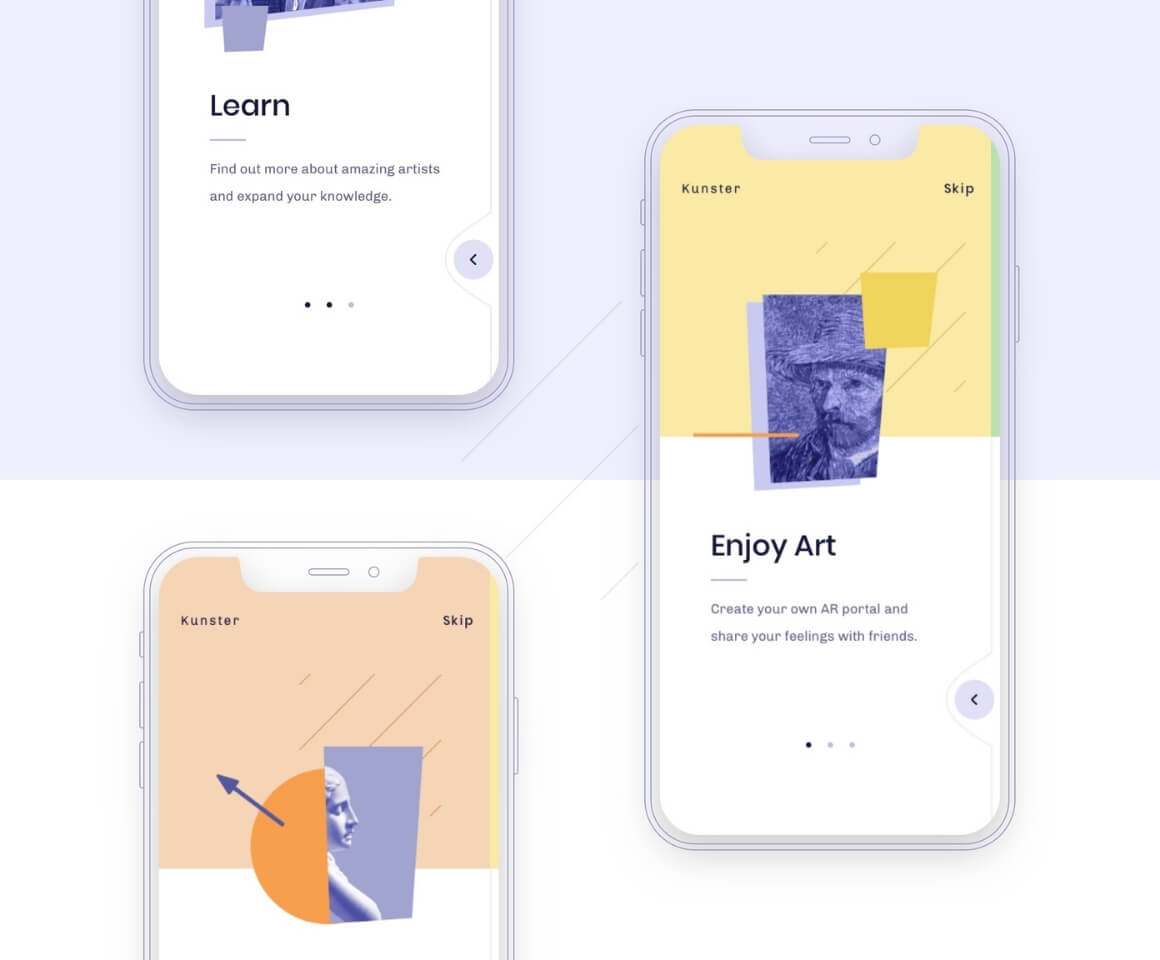
One of our latest R&D projects aims to show people that no matter where we are, art is all around us. It’s just a matter of perception. Ever wondered how Picasso saw the world around him? Or how would your room look if it was painted by Munch? Now you can use Kunster to check it.
The iOS application is based on Machine Learning and Augmented Reality. We used ARKit, CoreML, and TensorFlow Light to achieve our goals.
PyTorch allowed us to quickly develop a pipeline to experiment with style transfer - training the network, stylizing videos, incorporating stabilization, and providing the necessary evaluation metrics to improve the model. coremltools was the framework we used to integrate our style transfer models into the iPhone app, converting the model into the appropriate format and running video stylization on a mobile device.
Read the full case study here.
BabyGuard
-1.jpg?width=700&name=babyguard%20(1)-1.jpg)
A free, user friendly application that replaces electronic baby monitors. The app works over WiFi, not the Internet, so your baby’s data isn’t shared with any third-party servers.
Our team of ML engineers prepared a solution that detects baby cries and filters them out from all other noises around. In this way, the parents are always notified when the kid needs care.
Read the full case study here.
Future of Machine Learning
So we’ve established how Machine Learning is being used today, and how it can help businesses in various industries, but what does the future hold for this technology, and how do we overcome current challenges?

The first challenge that we will face when trying to solve any ML-related problem is the availability of the data. What we care about is both the quantity and quality of the data. It’s often not only about the technical possibility of measuring something but of making use of it. We often need to collect data in one place to make further analysis feasible.
Bearing this in mind, there are many tasks right now that lack the data to properly train the ML models, but such data will be available soon. What is going to generate a new source of data that are currently unavailable, but could be in the near future?
There are four main avenues to do this:
- IoT sensors,
- digitization of processes,
- sharing data that are generated and could be further used by third-parties,
- using ML for getting previously hard to acquire data that now can be collected cheaply.
Improvements in NLP
When people started to use language, a new era in the history of humankind started. We are still waiting for the same revolution in human-computer understanding, and we still have a long way to go.
But in the meantime, even though the computer may not fully understand us, it can pretend to do so, and yet be quite effective in the majority of applications. The field is developing rapidly. In fact, a quarter of all ML articles published lately have been about NLP, and we will see many applications of it from chatbots through virtual assistants to machine translators.
Reinforcement learning
Reinforcement learning is:
(...)area of machine learning concerned with how software agents ought to take actions in an environment so as to maximize some notion of cumulative reward.
Source: Wikipedia
So it’s all about creating programs that interact with the environment (a computer game or a city street) to maximize some reward, taking feedback from the environment. This finds a broad range of applications from robots figuring out on their own how to walk/run/perform some task to autonomous cars to beating game players (the last one is maybe the least practical one).
Improvements in image recognition
Improvement of image recognition is a bit similar to the NLP topic. For language processing, it’s all about making a computer understand what we are saying, whereas in Image Recognition we’d like to be on the same page when it comes to image inputs.
However, there is a significant difference – if a machine can spot a visual pattern that is too complex for us to comprehend, we probably won’t be too picky about it. But it’s a double-edged sword because machines can sometimes get lost in low-level noise and completely miss the point.
With our improvement of Image Recognition, algorithms are becoming capable of doing more and more advanced tasks with a performance similar to or even outperforming humans. They also never get bored and return results in a blink of an eye.
Popular Machine Learning terms to know
There is a lot of jargon associated with machine learning that can make it difficult to understand when reading about the topic. Below are a few of the most common terms you’ll see when working with ML, and their definitions.

Natural language processing
Natural language processing is a subfield of artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data.
Computer vision
Computer vision deals with how computers can gain high-level understanding from digital images or videos. From the perspective of engineering, it seeks to understand and automate tasks that the human visual system can do.
Data science
Data science uses scientific methods, processes, algorithms and systems to extract knowledge and insights from many structural and unstructured data. Data science is related to data mining, machine learning and big data.
Artificial intelligence
The theory and development of computer systems able to perform tasks normally requiring human intelligence, such as visual perception, speech recognition, decision-making, and translation between languages.
Machine learning
Machine learning is the study of computer algorithms that improve automatically through experience. It is seen as a part of artificial intelligence.
Learning algorithm
A learning algorithm is a method used to process data to extract patterns appropriate for application in a new situation. In particular, the goal is to adapt a system to a specific input-output transformation task.
Pattern recognition
Pattern recognition is the automated recognition of patterns and regularities in data. It has applications in statistical data analysis, signal processing, image analysis, information retrieval, bioinformatics, data compression, computer graphics and machine learning.
Deep learning
Deep learning is an artificial intelligence (AI) function that imitates the workings of the human brain in processing data and creating patterns for use in decision making.
Machine learning datasets
A dataset is a collection of data. In Machine Learning models, datasets are needed to train the model for performing various actions.
Supervised machine learning algorithms
Supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples.
Unsupervised machine learning algorithms
Unsupervised learning is a type of algorithm that learns patterns from untagged data. The hope is that through mimicry, the machine is forced to build a compact internal representation of its world.
Semi-supervised machine learning algorithm
Semi-supervised machine learning is a combination of supervised and unsupervised machine learning methods. In semi-supervised learning algorithms, learning takes place based on datasets containing both labeled and unlabeled data.
Reinforcement machine learning algorithms
Reinforcement learning (RL) is an area of machine learning concerned with how intelligent agents ought to take actions in an environment in order to maximize the notion of cumulative reward. Reinforcement learning is one of three basic machine learning paradigms, alongside supervised learning and unsupervised learning.
Self learning
In machine learning, self learning is the ability to recognize patterns, learn from data, and become more intelligent over time.
Feature learning
Feature learning or representation learning is a set of techniques that allows a system to automatically discover the representations needed for feature detection or classification from raw data.
Sparse dictionary learning
Sparse coding is a representation learning method which aims at finding a sparse representation of the input data in the form of a linear combination of basic elements as well as those basic elements themselves.
Anomaly detection
In data analysis, anomaly detection is the identification of rare items, events or observations which raise suspicions by differing significantly from the majority of the data.
Robot learning
Robot learning is a research field at the intersection of machine learning and robotics. It studies techniques allowing a robot to acquire novel skills or adapt to its environment through learning algorithms.
Chatbots
A chatbot is a type of software that can automate conversations and interact with people through messaging platforms.
Big data
Big data is a field that treats ways to analyze, systematically extract information from, or otherwise deal with data sets that are too large or complex to be dealt with by traditional data-processing application software.
Wrap up

While there are certainly some challenges involved with machine learning, and steps to be taken to improve it over the next few years, there’s no doubt that it can deliver a variety of benefits for any kind of business right now. Whether you want to increase sales, optimize internal processes or manage risk, there’s a way for machine learning to be applied, and to great effect.
The key is to take your time reviewing and considering the various algorithms and technologies used to build and develop ML models, because what works for one task might not be as good for another.
Beyond the jargon (and hopefully there was nothing on this page that we left unexplained), the clear strength of machine learning lies in its ability to process and analyse massive datasets, automate rules-based tasks and furnish business leaders with predictive analytics that can drive growth and scalability.
Hopefully this guide has given you all the information you need to know regarding machine learning, and given you an idea of where it might be helpful to your business.
If you’re still unsure, drop us a line so we can give you some more info tailored to your business or project. We’re expert ML engineers with bags of experience - just ask our clients.












