Handling Enormous Collection Types in Swift


You take Set if you want a collection type with unique unordered elements. But you do not care about performance or RAM usage, because they are often similar. Have you ever asked yourself what happens if your collection has to store almost 3 millions of elements like strings?
I have, because I am an author of unofficial iOS Scrabble dictionary – Scrabbdict. There is no problem with 3 of 4 available dictionaries: two English (SOWPODS and TWL) and French dictionaries are quite small, they contain from 178,691 to 386,264 words. Polish dictionary contains 2,964,259 words. And there is no simple solution to handle that big collection.
It was my first iOS app and I wrote it in 2013 in Objective-C. I remember it was working perfectly on iOS simulator, but when I bought my first developer license it was crashing a lot on a real device, because of too high memory usage. I resolved it by splitting Polish dictionary into multiple files:
- a basic one that was persistent in memory and contained words up to eight characters,
- additional files where each contains words that has 9, 10, 11, 12, 13, 14 or 15 letters, loaded when necessary.
It was reasonable and really fast especially for short words. Furthermore memory usage was acceptable.
I used Array and loading a dictionary was as simple as this:
NSString *langCode;
NSArray *dictArray = [NSString stringWithContentsOfFile:[[NSBundle mainBundle] pathForResource:langCode ofType:@"txt"] encoding:NSUTF8StringEncoding error:nil] componentsSeparatedByCharactersInSet:[NSCharacterSet whitespaceAndNewlineCharacterSet]];
But handling this was inconvenient and limited possibilities.
When working on 3.0 update I decided to implement more complex features like points for all words and simple regex (blanks) support. I knew that a key to this is better performance. Now I want to share with you different solutions to the problem and let you know what technique Scrabbdict actually uses.
Collection types
- Arrays
- Standard
Array Arraywith reserved capacity that equals a count of stringsContiguousArrayContiguousArraywith reserved capacity that equals a count of stringsCleverArraythat is standard two-dimensionalArraywhere arrays inside contains words with letters count that equals an index of array- Sets
- Standard
Set CleverSetthat is standardArrayof standardSetswhere sets inside contains words with letters count that equals an index of set- Tries
- Modified
Triefrom Buckets-Swift by Mauricio Santos - Realm database
- Standard
Realmdatabase withListofStringObjects CleverRealmdatabase with multipleListsofStringObjects where each list contains words with different letters count
Standard vs clever collection
To show the difference between "standard" and "clever" collection type objects I created this graphic:

So when we discuss Array, then standard is Array<String> and clever is Array<Array<String>>.
Source code
Disclaimer: I am not going to post here all source code, but you can take a look at the repository, which I strongly advise!
Each one of mentioned collection type implements Validator protocol:
protocol Validator: class {
init()
/// Returns a Boolean value indicating whether
/// the Polish dictionary contains the given word.
/// - parameter word: The word to validate.
func validate(word: String) -> Bool
/// Returns an array of words that can be made from the given letters.
/// - parameter letters: The letters.
func words(from letters: String) -> [String]?
}
More advanced collections (which equal faster) implement CleverValidator protocol, which allows the same, but it adds simple regex query.
protocol CleverValidator: Validator {
/**
Returns an array of words that fit the given regex query.
An example of correct query:
regex(phrase: "pr??lem") // ["preclem", "problem"]
- parameter phrase: The simple regex query.
Only letters and blanks (`?`) are allowed.
*/
func regex(phrase: String) -> [String]?
}
I believe these are clear.
Before I'll let you see the results, I'd like you to see the most basic validator class:
/// Simple word validator based on array of strings.
final class ArrayWordValidator: Validator {
/// An array of strings.
private let words: [String]
init() {
let string = try! String(contentsOf: fileURL, encoding: .utf8)
words = string.components(separatedBy: .newlines)
}
func validate(word: String) -> Bool {
return words.contains(word.lowercased())
}
func words(from letters: String) -> [String]? {
let permutes = letters.lowercased()
.map { String($0) }
.permute()
let predicate = NSPredicate(format: "SELF IN %@", permutes)
return words.filter { predicate.evaluate(with: $0) }
}
}
The initialization and validation function are self-explanatory. The function that returns words that can be made from given letters may be not.
First, it gets all possible permutes from given letters. To make it faster minimum length of permute is 2 characters, because single letter words are not valid in Scrabble. Then, creates a somewhat forgotten NSPredicate object. You may ask why and that is a very good question.
The same result can be achieved in at least two ways here:
let a = permutes.filter { words.contains($0) }
let b = words.filter { predicate.evaluate(with: $0) }
Unfortunately the first solution is extremely slow. When permutes counts 86 strings (that happens for five letters query) and the first solution is used, it takes around 170 seconds to return results. The latter solution needs less than eight seconds (sic!). The more permutes, the difference is bigger.
Results
I'd like to present you results of multiple performance tests for different collection types.
Let's start from something simple, but important…
Initialization time
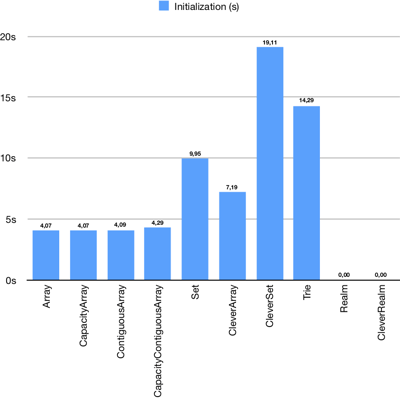
There is no big difference between the first four arrays, but CleverSet and Trie initialization time is simply unacceptable. Both Realm and CleverRealm initialization time is unnoticeable, because of Realm laziness.
Word validation
Just simple word validation – the result is a boolean value that determines if a word is correct or not. Each validator validates 15 words one by one in this test.
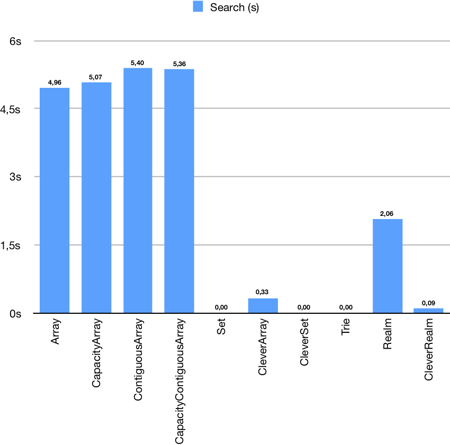
Again, there is no big difference between the first four arrays. Sets and trie are extremely fast. Set because of object uniqueness and trie because of its structure. Standard arrays are simply slowest, but clever objects look really good. Especially CleverRealm when count init time in.
Words made from given letters
That's really interesting!
Imagine that I give letters I, T and L, and expect words that can be made from them. So lit, til, it, li and ti should be returned. So it's the same, but in Polish :)
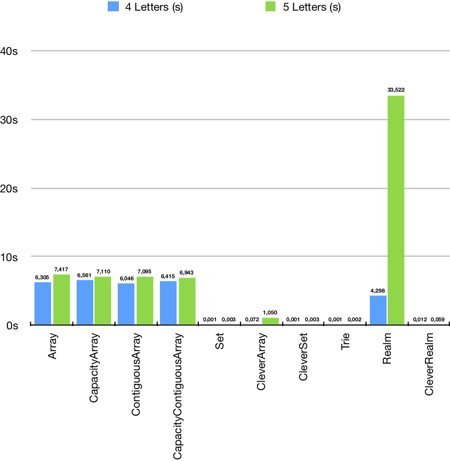
The results are a bit surprising. There is a huge difference between 4 and 5 letters for standard Realm database. Sets, trie, CleverArray and CleverRealm are really fast in this test, so I decided to run more tests for the fastest four of them.
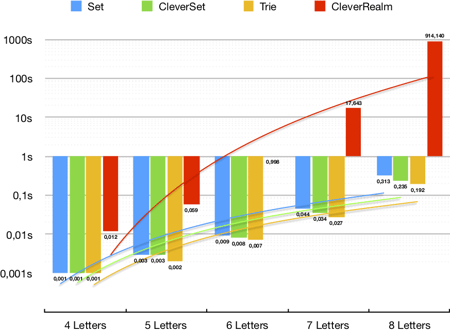
This chart has logarithmic scale with power trend line.
Sets and trie growth when more letters is reasonable, but CleverRealm is useless for more than six letters!
Simple regex
This test results with a time time needed to find words that fit these simple blank regex one by one: p?z?a, ???, po??r, pap????, ???????, tele???.
In example: po??r should return pobór, poder, poker, pokór, polar, poler, polor, pomór, ponor, ponur, potir, power, pozer, pozór, pożar.
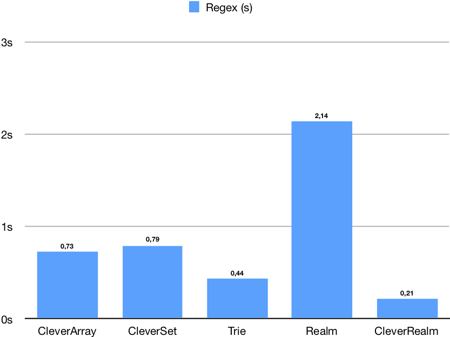
This is possible in reasonable time only for CleverArray, CleverSet, Trie, Realm and CleverRealm.
CleverRealm is the fastest, while Realm is the slowest. Important thing is that Trie is faster than standard Swift collection types.
RAM Usage
Last, but not least – it eventually makes some types useless.
RAM usage measured by Xcode profiler on a real device running example app:
- RAM Usage is RAM usage just after initialization.
- Highest RAM Usage is the highest RAM usage noticed during initialization.
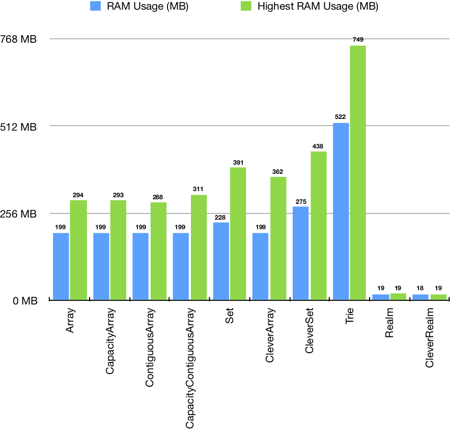
As you can see trie and sets RAM usage is unacceptable high, because it may cause crashes especially on older devices. Arrays RAM usage is high, but acceptable – unfortunately their performance is not satisfactory. Realm RAM usage is close to null.
Judgment
It's really hard to say which collection type is the best. No one is perfect and the same applies here.
I believe that the best solution is to use more than one technique at once and that's how Scrabbdict works. Normally it uses solution similar to CleverRealm database – it's fast for word validation and simple regexes. But when the app is started, in background it creates a trie with words up to 8 letters and uses it to find words made from given letters. In Scrabble you can't have more than seven tiles on your hand, so eight letters limit is still fine and a trie is really fast.
Such limited trie (there are just less than half a million words up to 8 letters in Polish) initializes quite fast (but it really doesn't matter so much, because it happens in background) and is one the fastest solutions.