🤖 MLguru #2: Generative Adversarial Networks, DeepFill v2, Fraudulent Network Traffic with GANs, NIPS 2018, and News from Google
-450071-edited.jpg?width=50&height=50&name=Opala%20Mateusz%202%20(1)-450071-edited.jpg)

This week we’ll dive deeper into Generative Adversarial Networks and their applications. We’ll also present a recently discovered method for image inpainting and some ML products from Google. Enjoy!
GANs everywhere - Self-attention GAN
A Generative Adversarial Network (GAN) is a generative machine learning model that consists of two networks: a generator and a discriminator. The generator tries to fool the discriminator by generating synthetic data that is difficult to distinguish. The discriminator tries to determine whether the data is real or fake. During training, both the generator and the discriminator get better at their tasks. At the, the end generator is capable of generating data that looks like the real thing. GANs have a lot of interesting applications, for example image-to-image translation.
Here you can check out a model called STARGan, which performs image-to-image translation for multiple domains. One of the fathers of modern deep learning, Yan Lecun, called GANs the most important thing to explore in research currently.
The classic problem with GANs is that they are really good at generating synthetic images in a bunch of different domains, but they struggle to model aspects of images that require understanding of a whole, like getting the number of animal legs right.
The father of GANs, Ian Goodfellow, along with some other researchers published a work on Self-attention Generative Adversarial Networks (SAGAN). "The self-attention module is complementary to convolutions and helps with modeling long range, multi-level dependencies across image regions. Armed with self-attention, the generator can draw images in which fine details at every location are carefully coordinated with fine details in distant portions of the image," they wrote.
SAGAN outperforms the previous state-of-the art obtaining a 52,52 Inception score in comparison to 36,8 for the previous best published result.
The Inception Score measures the Kullback-Leibner divergence between conditional class distribution and marginal class distribution. Higher values are better. In practice, the Inception Score is high when:
- Generated images contain a clear object (sharp rather than blurry - conditional class distribution should have low entropy)
- The generator is able to generate high diversity of images (marginal class distribution should have high entropy)
Here are some sample results from the paper:

Source: https://arxiv.org/pdf/1805.08318.pdf
More info:
DeepFill v2
Recently we’ve come across DeepFill v1 for image inpainting. DeepFill v1 is basically a fully convolutional neural network that introduces the Contextual Attention module. CNNs have struggled to generate clear images due to the ineffectiveness of copying information from distant locations. The Contextual Attention module tries to solve this problem by learning where to borrow or copy information from the known background to the missing foreground. It consists of a convolution layer, a softmax layer to get attention score for each pixel, and deconvolution for reconstruction. We’re very impressed with the results:

Source: http://jiahuiyu.com/deepfill/
There’s also a project page when you can try it out interactively.
After a couple of months, the authors improved their method and have released DeepFill v2. And the results seems to be even more impressive!

Source: http://jiahuiyu.com/deepfill2/
DeepFill v2 is based on Gated Convolutions. The vanilla convolutions used in DeepFill v1 are ill-fitted for free-form image inpainting. In vanilla convolution, the same filters are applied to compute the output for al spatial locations. This is a desired behavior for tasks such as image classification or object detection, where all pixels of the input image are valid. However, in the case of image inpainting the input images consist of valid pixels, holes and synthetized pixels (in deep layers). This leads to image distortions and blurriness. Gated Convolutions learn the soft max for dynamic feature selection for each channel and each spatial location. Furthermore, the authors introduced a new GAN loss to handle irregular shapes. Unfortunately, they haven’t released code or a demo yet, but you can watch this YouTube video they provided:
Maybe we should think about using this in next version of the PrettyCity app?
Creating fraudulent network traffic with GANs
With the spread of security threats, machine learning algorithms have been widely used in Intrusion Detection Systems (IDSs) and achieved good results. However, with the raise of Generative Adversarial Networks (GANs), IDSs have become vulnerable to adversarial attacks.
A couple of days ago researchers from Shanghai have published a paper on training GANs based on the Wasserstein GAN (here’s a good article on the Wasserstein GAN) that generates malicious traffic examples which can deceive and evade the detection of defense systems called IDSGANs.
They use the NSL-KDD dataset for testing and a variety of different algorithms to play the role of the intrusion detection system, including SVMs, logistic regressions, decision trees, random forest, and k-nearest neighbour. Tests show that IDSGAN causes a significant drop in detection rates from around 70-80% to around 3-8% across the entire suite of methods. However, keep in mind that NSL-KDD is just a benchmark dataset and may not be a perfect representative of real networks.
You can read more here.
Google announces datasets search
A couple of days ago Google has released a search engine for machine learning datasets and pretrained models. It’s a beta version and you can try it here.
It finds PyTorch models, so it’s not completely biased ;)
Google releases Dopamine - not a Google Product
Google has released Dopamine - a research framework for fast prototyping of reinforcement learning algorithms. It’s shipped with Deep Q Learning, Rainbow, C51 and Implicit Quantile Networks. The software aims to make running experiments and trying out research ideas easy. However, they mention in the README.md that it’s not an official Google Product, so it’s hard to say whether it will stand the test of time.
You can check github repository here.
NIPS 2018
NIPS, a conference on Neural Information Processing Systems, is one of the most famous conferences in the Machine Learning world. This year the tickets sold out in 10 minutes! Half an hour after sales started I saw posts on Facebook from people who wanted to buy tickets like it was a Bon Jovi concert!
The whole this situation reminded me of ML_Hipster’s prediction from last year about when the ML singularity will arrive :D
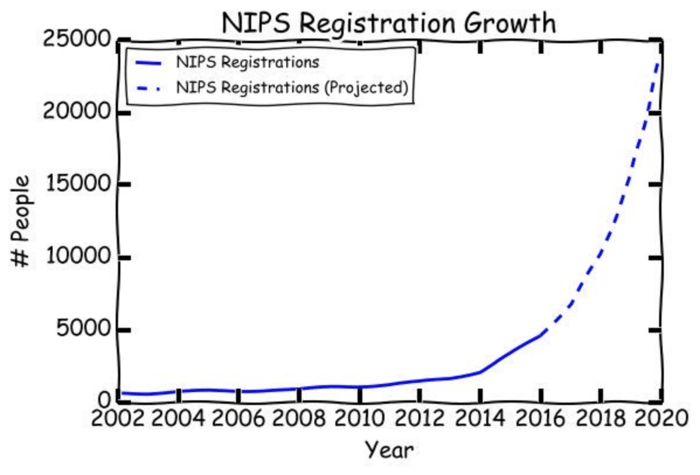
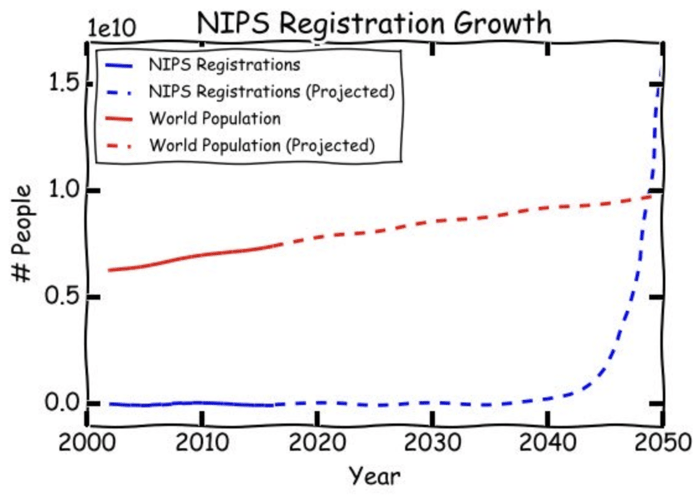
Source: ML_Hipster
ML Forum
Tomorrow (18th September 2018), I’ll be speaking at the ML Forum in Warsaw. My presentation will be focused on ML models’ predictions, and there will be a lot of other interesting speakers too. I know it’s quite short notice to still sign up, but don’t worry – I’ll share the top highlights in the next MLguru!
Meanwhile, I hope you’ve enjoyed my news and interesting facts. Have a great week!
-450071-edited.jpg?width=260&height=260&name=Opala%20Mateusz%202%20(1)-450071-edited.jpg)



















